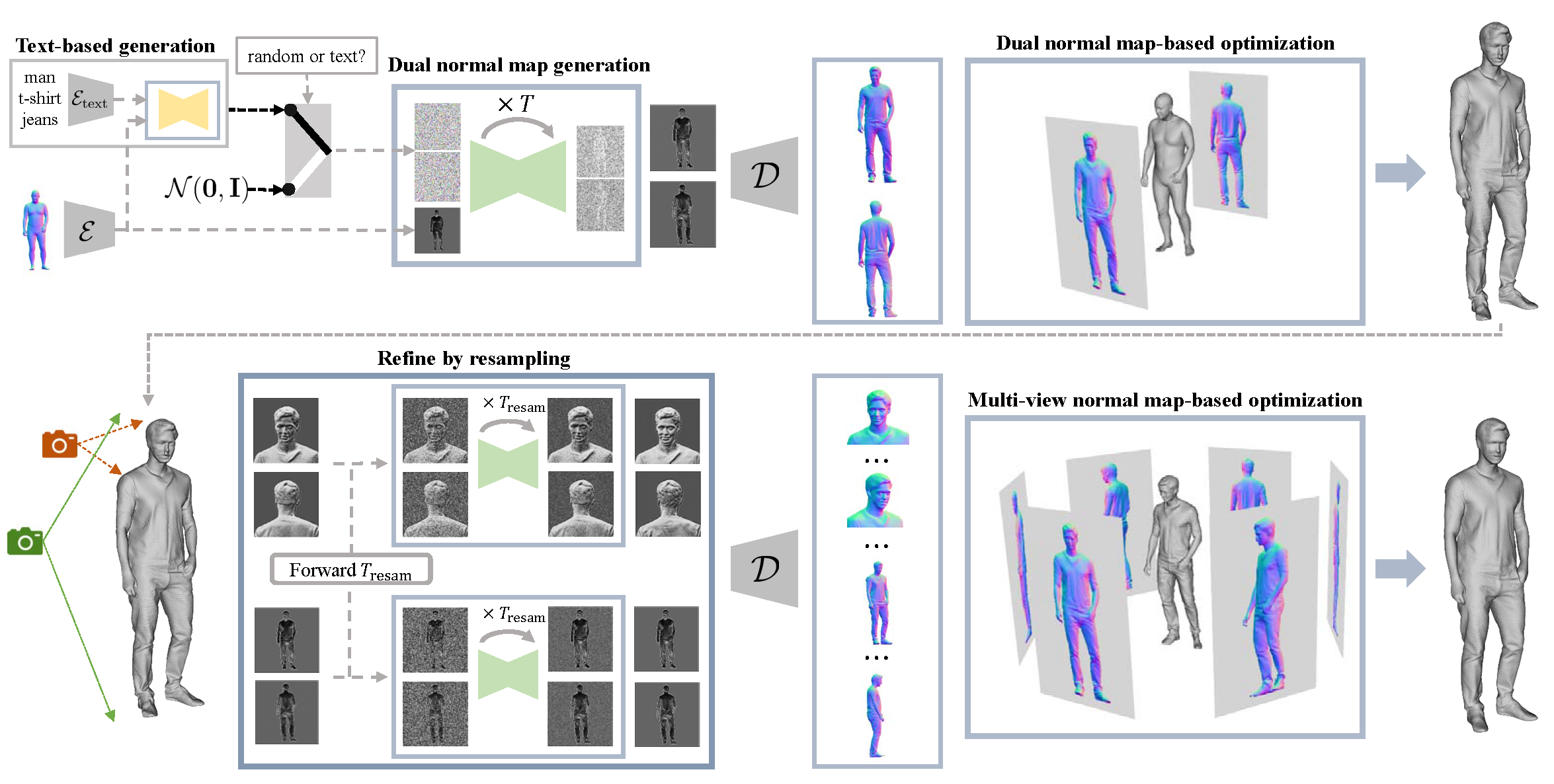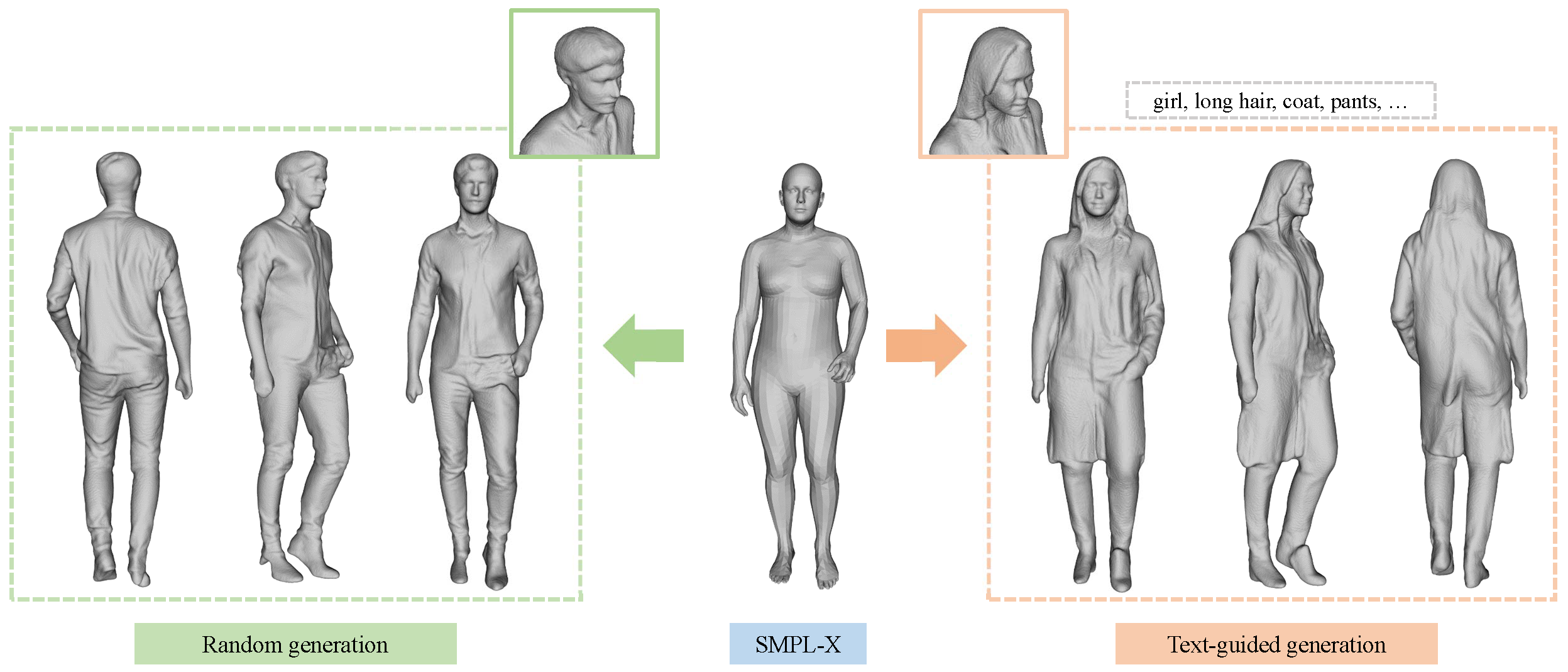
We propose a 3D generation pipeline that uses diffusion models to generate realistic human digital avatars. Due to the wide variety of human identities, poses, and stochastic details, the generation of 3D human meshes has been a challenging problem. To address this, we decompose the problem into 2D normal map generation and normal map based 3D reconstruction. Specifically, we first simultaneously generate realistic normal maps for the front and backside of a clothed human using pose-conditional diffusion models. For 3D reconstruction, we "carve" the prior SMPL mesh to a detailed 3D mesh according to the normal maps through mesh optimization. To further enhance the high-frequency details, we present a diffusion resampling scheme on both body and facial regions, thus encouraging the generation of realistic digital avatars. We also seamlessly incorporate a recent text-to-image diffusion model to support text-based human identity control. Our method, namely, Chupa, is capable of generating realistic 3D clothed humans with better perceptual quality and identity variety.
@InProceedings{kim2023chupa,
author = {Kim, Byungjun and Kwon, Patrick and Lee, Kwangho and Lee, Myunggi and Han, Sookwan and Kim, Daesik and Joo, Hanbyul},
title = {Chupa: Carving 3D Clothed Humans from Skinned Shape Priors using 2D Diffusion Probabilistic Models},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {15965-15976}
}