Guess The Unseen:
Dynamic 3D Scene Reconstruction from Partial 2D Glimpses
CVPR 2024
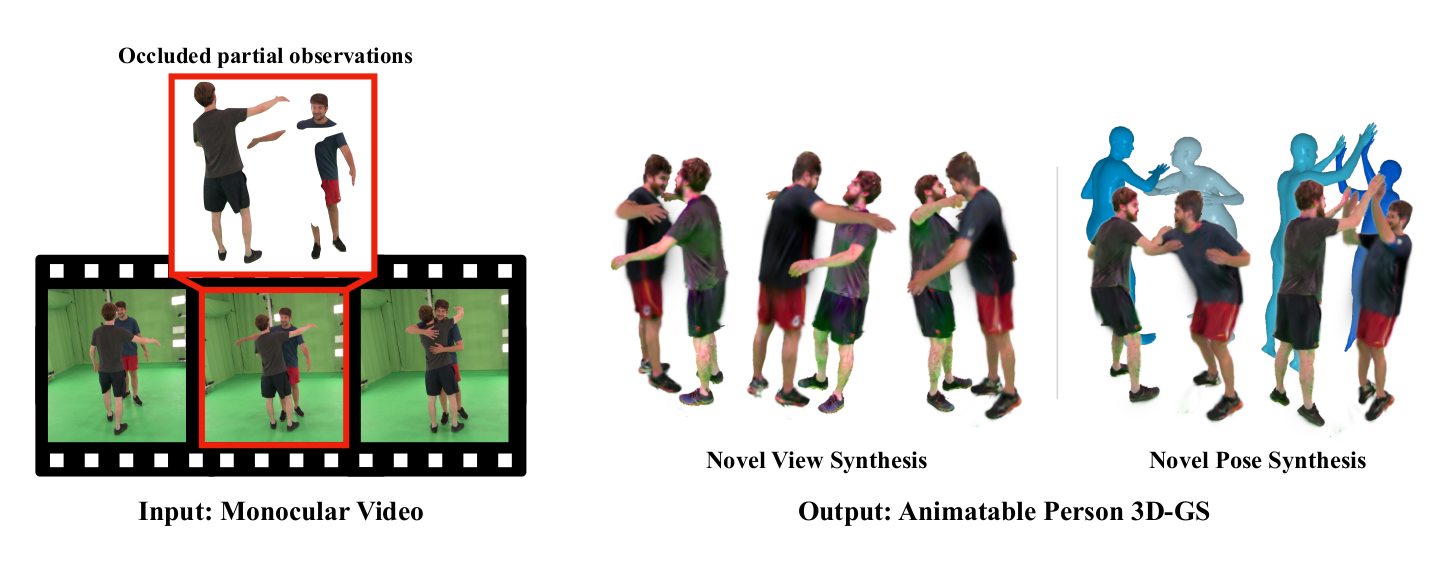
In this paper, we present a method to reconstruct the world and multiple dynamic humans in 3D from a monocular video input. As a key idea, we represent both the world and multiple humans via the recently emerging 3D Gaussian Splatting (3D-GS) representation, enabling to conveniently and efficiently compose and render them together. In particular, we address the scenarios with severely limited and sparse observations in 3D human reconstruction, a common challenge encountered in the real world. To tackle this challenge, we introduce a novel approach to optimize the 3D-GS representation in a canonical space by fusing the sparse cues in the common space, where we leverage a pre-trained 2D diffusion model to synthesize unseen views while keeping the consistency with the observed 2D appearances. We demonstrate our method can reconstruct high-quality animatable 3D humans in various challenging examples, in the presence of occlusion, image crops, few-shot, and extremely sparse observations. After reconstruction, our method is capable of not only rendering the scene in any novel views at arbitrary time instances, but also editing the 3D scene by removing individual humans or applying different motions for each human. Through various experiments, we demonstrate the quality and efficiency of our methods over alternative existing approaches.
This work was supported by Samsung Electronics C-Lab, NRF grant funded by the Korea government (MSIT) (No. 2022R1A2C2092724 and No. RS-2023-00218601), and IITP grant funded by the Korean government (MSIT) (No.2021-0-01343). H. Joo is the corresponding author.
@article{lee2024gtu,
title={Guess The Unseen: Dynamic 3D Scene Reconstruction from Partial 2D Glimpses},
author={Inhee Lee and Byungjun Kim and Hanbyul Joo},
year={2024},
eprint={2404.14410},
archivePrefix={arXiv},
primaryClass={cs.CV}
}